模型可解释性
这是一个关于错误解释机器学习模型的危险以及正确解释它的价值的故事。如果您发现诸如梯度提升机或随机森林之类的集成树模型的鲁棒准确性很有吸引力,但也需要解释它们,那么我希望您发现这些信息有用且有帮助。
试想一下,我们的任务是预测个人Ô为n行的财务状况。我们的模型越准确,银行赚的钱就越多,但由于此预测用于贷款申请,因此法律上也要求我们解释为什么做出预测。在对多种模型类型进行试验后,我们发现 XGBoost 中实现的梯度提升树提供了最佳准确度。不幸的是,解释 XGBoost 做出预测的原因似乎很难,所以我们只能选择退回到线性模型,或者弄清楚如何解释我们的 XGBoost 模型。没有数据科学家愿意放弃准确性……所以我们决定尝试后者,并解释复杂的 XGBoost 模型(它恰好有 1,247 个深度为 6 的树)。

经典的全局特征重要性度量
第一个明显的选择是使用 Python XGBoost 接口中的 plot_importance() 方法。它提供了一个非常吸引人的简单条形图,表示我们数据集中每个特征的重要性:(重现本文的代码在Jupyter notebook 中)
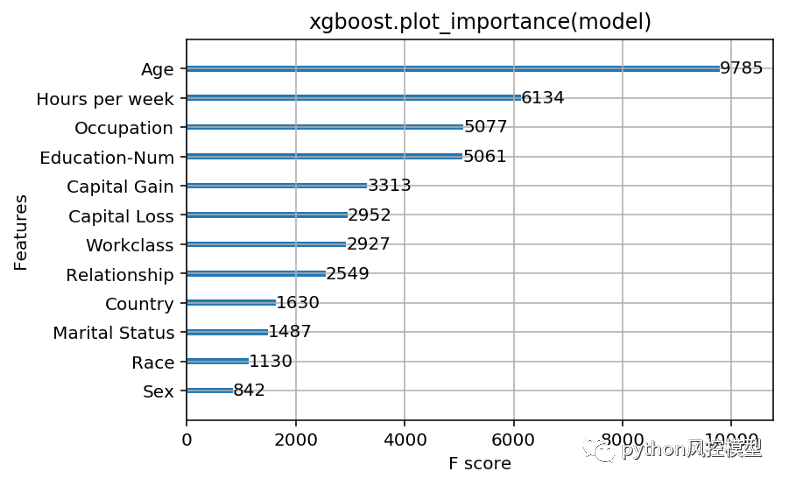
为一个训练模型运行 xgboost.plot_importance(model) 的结果,用于预测人们是否会报告来自经典“成人”人口普查数据集的超过 5 万美元的收入(使用逻辑损失)。
如果我们查看 XGBoost 返回的特征重要性,我们会发现年龄在其他特征中占主导地位,显然是最重要的收入预测指标。我们可以停在这里,向我们的经理报告直观令人满意的答案,即年龄是最重要的特征,其次是每周工作时间和教育水平。但是作为优秀的数据科学家……我们查看了文档,发现在 XGBoost 中测量特征重要性有三个选项:
-
重量。使用特征在所有树中拆分数据的次数。
-
覆盖。使用特征在所有树中拆分数据的次数,权重由经过这些拆分的训练数据点的数量决定。
-
获得。 使用特征进行拆分时获得的平均训练损失减少量。
这些是我们可以在任何基于树的建模包中找到的典型重要性度量。权重是默认选项,因此我们决定尝试其他两种方法,看看它们是否有所不同:
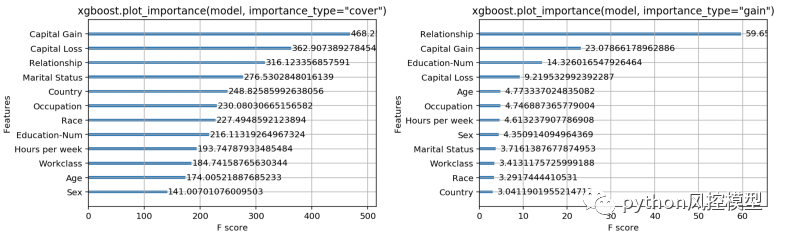
运行 xgboost.plot_importance 的结果同时具有 important_type=”cover” 和 important_type=”gain”。
令我们沮丧的是,我们看到 XGBoost 提供的三个选项中的每一个的特征重要性排序都非常不同!对于cover方法,似乎资本收益特征最能预测收入,而对于收益方法,关系状态特征主导所有其他特征。这应该让我们在不知道哪种方法最好的情况下,依赖这些度量来报告特征重要性会非常不舒服。
是什么让衡量特征重要性的好坏?
如何将一种特征归因方法与另一种进行比较并不明显。我们可以衡量每种方法在数据清理、偏差检测等任务上的最终用户性能。但这些任务只是对特征归因方法质量的间接衡量。在这里,我们将改为定义我们认为任何好的特征归因方法都应该遵循的两个属性:
-
一致性。每当我们更改模型以使其更多地依赖于某个特征时,该特征的归因重要性不应降低。
-
准确性。所有特征重要性的总和应该等于模型的总重要性。(例如,如果重要性是由 R² 值衡量的,那么每个特征的属性应与完整模型的 R² 相加)
如果一致性不成立,那么我们不能比较任意两个模型之间的归因功能重要性有关,因为那么 具有较高分配的归属并不意味着模型实际上更多地依赖于该功能。
如果准确性无法保持,那么我们不知道每个特征的属性如何结合起来代表整个模型的输出。我们不能在方法完成后对属性进行标准化,因为这可能会破坏方法的一致性。
当前的归因方法是否一致且准确?
回到我们作为银行数据科学家的工作……我们意识到一致性和准确性对我们很重要。事实上,如果一个方法不一致,我们不能保证具有最高属性的特征实际上是最重要的。因此,我们决定使用两个与我们在银行的任务无关的非常简单的树模型来检查每种方法的一致性:
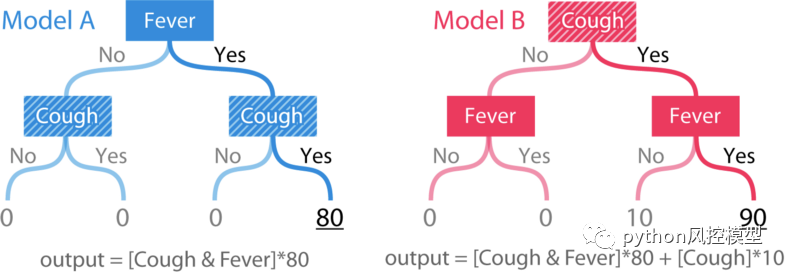
两个特征的简单树模型。咳嗽在模型 B 中显然比模型 A 更重要。
模型的输出是基于人的症状的风险评分。模型 A 只是一个简单的“与”函数,用于发烧和咳嗽的二元特征。模型 B 具有相同的功能,但只要咳嗽是肯定的,就 +10 。为了检查一致性,我们必须定义“重要性”。在这里,我们将通过两种方式定义重要性:1)作为我们删除一组特征时模型预期准确率的变化。2)作为我们删除一组特征时模型预期输出的变化。
重要性的第一个定义衡量特征对模型的全局影响。而第二个定义衡量特征对单个预测的个性化影响。在我们的简单树模型中,咳嗽特征在模型 B 中显然更重要,无论是对于全局重要性还是对于发烧和咳嗽都是肯定的个体预测的重要性。
上面的weight、cover和gain方法都是全局特征归因方法。但是当我们在银行中部署我们的模型时,我们还需要为每个客户提供个性化的解释。为了检查一致性,我们在简单的树模型上运行了五种不同的特征归因方法:
-
树形状。我们提出了一种新的个性化方法。
-
萨巴斯。一种个性化的启发式特征归因方法。
-
平均值(|树形状|)。基于个性化 Tree SHAP 归因的平均幅度的全局归因方法。
-
获得。与上面 XGBoost 中使用的方法相同,也等效于 scikit-learn 树模型中使用的 Gini 重要性度量。
-
拆分计数。代表 XGBoost 中密切相关的“权重”和“覆盖”方法,但使用“权重”方法计算。
-
排列。当在测试数据集中随机排列单个特征时,导致模型准确度下降。
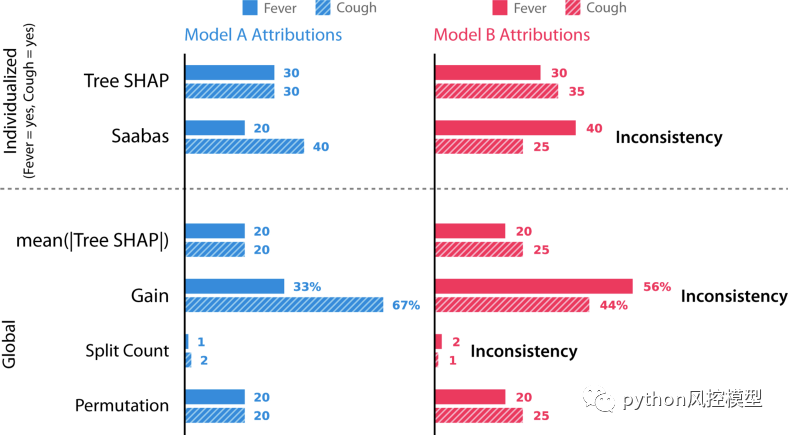
使用六种不同方法的模型 A 和模型 B 的特征属性。据我们所知,这些方法代表了文献中所有特定于树的特征归因方法。
之前除了特征排列以外的所有方法都是不一致的!这是因为它们在模型 B 中对咳嗽的重要性低于模型 A。不能相信不一致的方法可以正确地为最有影响的特征分配更多的重要性。精明的读者会注意到,当我们研究的经典特征归因方法在同一模型上相互矛盾时,这种不一致就已经在早些时候表现出来了。那么精度属性呢?事实证明,Tree SHAP、Sabaas 和 Gain 都如之前定义的那样准确,而特征排列和拆分计数则不然。
也许令人惊讶的是,像增益(基尼重要性)这样广泛使用的方法会导致如此明显的不一致结果。为了更好地理解为什么会发生这种情况,让我们检查一下模型 A 和模型 B 的增益是如何计算的。为了简单起见,我们假设我们的数据集的 25% 落在每个叶子上,并且每个模型的数据集都有完全匹配的标签模型的输出。
如果我们将均方误差 (MSE) 视为我们的损失函数,那么在对模型 A 进行任何拆分之前,我们从 1200 的 MSE 开始。这是来自 20 的常数平均预测的误差。在模型 A 中对发烧进行拆分后, MSE 下降到 800,因此增益方法将 400 的下降归因于发烧特征。然后在咳嗽特征上再次拆分导致 MSE 为 0,并且增益方法将这个 800 的下降归因于咳嗽特征。在模型 B 中,相同的过程导致分配给发烧特征的重要性为 800,分配给咳嗽特征的重要性为 625 :
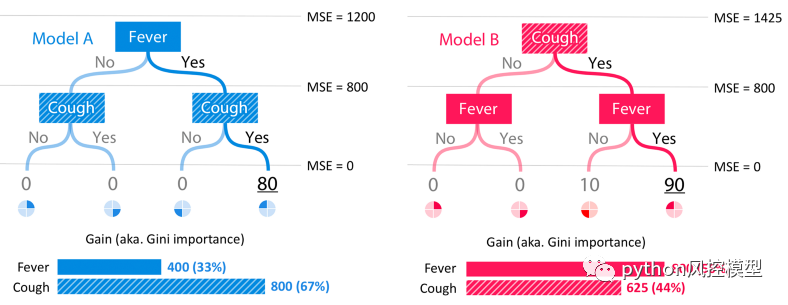
计算模型 A 和模型 B 的增益(又名基尼重要性)分数。
通常我们期望树根附近的特征比叶子附近分裂的特征更重要(因为树是贪婪地构造的)。然而,增益方法倾向于将更多的重要性归因于较低的分裂。这种偏见会导致不一致,当咳嗽变得更加重要时(因此从根本上分开),其归因重要性实际上下降了。个性化的 Saabas 方法(由treeinterpreter 使用package) 在我们下降树时计算预测的差异,因此它也遭受相同的偏向于树中较低的分裂。随着树变得更深,这种偏差只会增加。相比之下,Tree SHAP 方法在数学上等效于对特征的所有可能排序的预测差异进行平均,而不仅仅是由它们在树中的位置指定的排序。
只有 Tree SHAP 既一致又准确,这并非巧合。鉴于我们想要一种既一致又准确的方法,结果证明只有一种方法可以分配特征重要性。详细信息在我们最近的NIPS 论文中,但总结是博弈论关于利润公平分配的证明导致机器学习中特征归因方法的唯一性结果。这些独特的值被称为 Shapley 值,以 1950 年代导出它们的 Lloyd Shapley 的名字命名。我们在此使用的 SHAP 值来自与 Shapley 值相关的几种个性化模型解释方法的统一。Tree SHAP 是一种快速算法,可以在多项式时间内准确计算树的 SHAP 值,而不是经典的指数运行时(参见arXiv)。
自信地解释我们的模型
坚实的理论论证和快速实用的算法相结合,使 SHAP 值成为自信地解释树模型(例如 XGBoost 的梯度提升机)的强大工具。有了这种新方法,我们又回到了解释银行 XGBoost 模型的任务上:
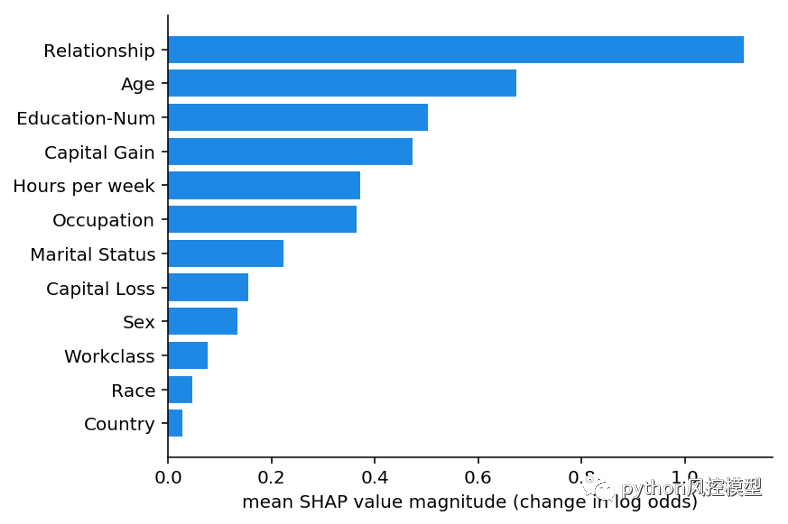
应用于收入预测模型的全局均值(|Tree SHAP|)方法。x 轴本质上是当特征从模型中“隐藏”时模型输出的平均幅度变化(对于该模型,输出具有对数几率单位)。有关详细信息,请参阅论文,但“隐藏”意味着将变量整合到模型之外。由于隐藏特征的影响会根据还隐藏的其他特征而变化,因此使用 Shapley 值来确保一致性和准确性。
我们可以看到,关系特征实际上是最重要的,其次是年龄特征。由于 SHAP 值保证了一致性,因此我们无需担心在使用增益或拆分计数方法之前发现的各种矛盾。但是,由于我们现在对每个人都有个性化的解释,因此我们可以做的不仅仅是制作条形图。我们可以绘制数据集中每个客户的特征重要性。在十八Python包让一切变得简单。我们首先调用 shap.TreeExplainer(model).shap_values(X) 来解释每个预测,然后调用 shap.summary_plot(shap_values, X) 来绘制这些解释:
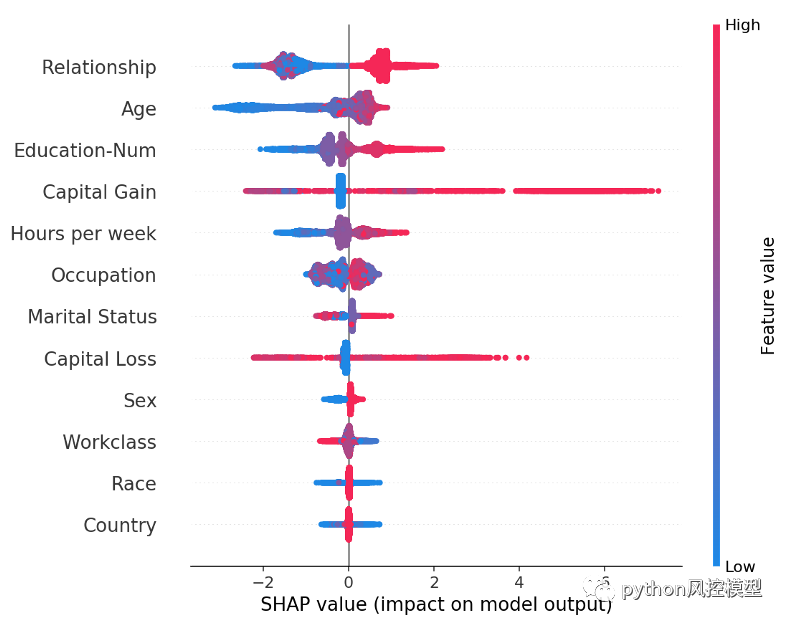
每个客户的每一行都有一个点。点的 x 位置是该特征对模型对客户的预测的影响,点的颜色代表该特征对客户的价值。不适合行的点堆积起来以显示密度(在此示例中有 32,561 个客户)。由于 XGBoost 模型具有逻辑损失,因此 x 轴具有对数赔率单位(Tree SHAP 解释了模型边际输出的变化)。
这些特征按均值(|Tree SHAP|)排序,因此我们再次将关系特征视为年收入超过 5 万美元的最强预测因子。通过绘制特征对每个样本的影响,我们还可以看到重要的异常值效应。例如,虽然资本收益在全球范围内并不是最重要的特征,但对于部分客户而言,这是迄今为止最重要的特征。按特征值着色的模式向我们展示了诸如年轻如何降低您赚取超过 5 万美元的机会,而高等教育增加您赚取超过 5 万美元的机会。
我们可以停在这里向我们的老板展示这个情节,但让我们更深入地研究其中的一些功能。我们可以通过绘制年龄 SHAP 值(对数几率的变化)与年龄特征值来为年龄特征做到这一点:
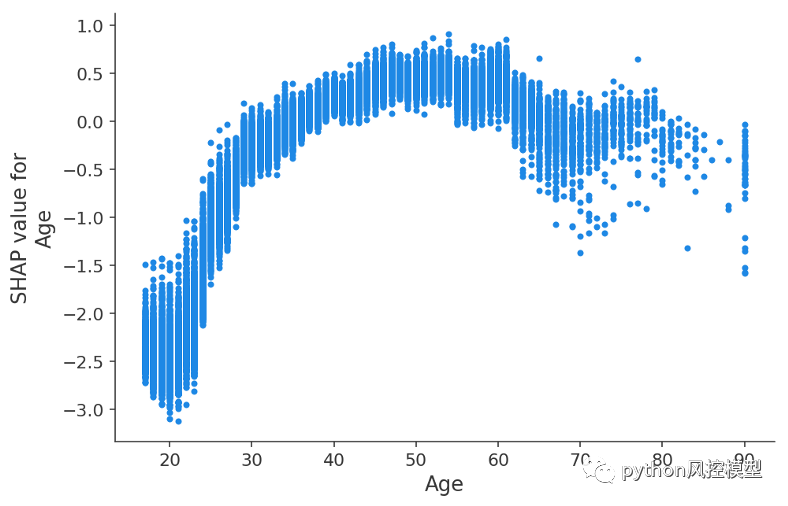
y 轴是年龄特征对年收入超过 5 万美元的对数几率的改变程度。x 轴是客户的年龄。每个点代表数据集中的一个客户。
在这里,我们看到了 XGBoost 模型捕捉到的年龄对收入潜力的明显影响。请注意,与传统的部分依赖图(显示更改特征值时的平均模型输出)不同,这些 SHAP 依赖图显示交互效应。尽管数据集中的许多人都 20 岁,但他们的年龄对他们的预测的影响程度有所不同,如 20 岁点的垂直离散所示。这意味着其他特征正在影响年龄的重要性。为了了解哪些特征可能是这种效应的一部分,我们根据受教育年限对点进行着色,并看到高水平的教育在 20 多岁时降低了年龄的影响,但在 30 多岁时提高了它:
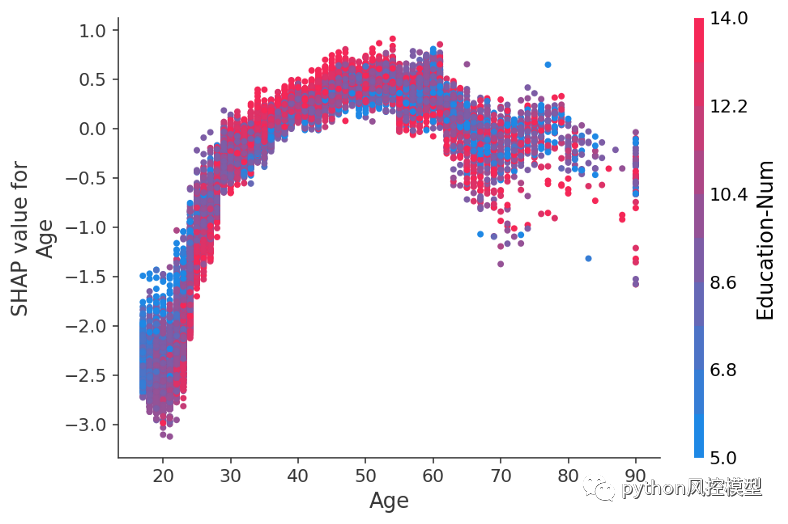
y 轴是年龄特征对年收入超过 5 万美元的对数几率的改变程度。x 轴是客户的年龄。Education-Num 是客户完成的教育年数。
如果我们为每周工作的小时数制作另一个依赖图,我们会看到工作更多的好处在大约 50 小时/周时稳定下来,如果您已婚,额外工作不太可能表明高收入:
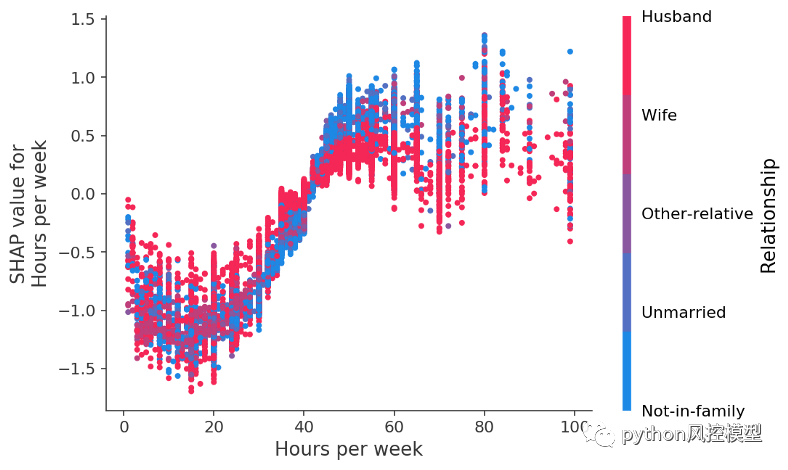
每周工作小时数与工作小时数对收入潜力的影响。
解释你自己的模型
这个简单的演练旨在反映您在设计和部署自己的模型时可能经历的过程。在十八包很容易通过PIP安装,我们希望它可以帮助你有信心开拓您的模型。它包含的不仅仅是本文所涉及的内容,包括 SHAP 交互值、模型不可知的 SHAP 值估计和其他可视化。笔记本可以在各种有趣的数据集上说明所有这些功能。例如,您可以在解释 XGBoost 死亡率模型的笔记本中根据您的健康检查查看您死亡的主要原因。对于 Python 以外的语言,Tree SHAP 也已直接合并到核心 XGBoost 和 LightGBM 包中。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。